Sobre SRE

Ah!… eu lembro quando se chamava Arquiteto de Soluções a figura do técnico que teve o maior volume de experiências com desenvolvimento e implantação de sistemas em larga escala, com alta disponibilidade, Disaster Recovery, Backup e etc…
Ele era O cara 😬
Mas isso já faz muito tempo e agora vivemos em uma época de procura efervescente na adoção das práticas de SRE e DevOps…
Então o que é SRE (Site Reliability Engineering) e o que significa?
Antes de mais nada, SREs são Engenheiros, que aplicam princípios de ciências da computação e engenharia para desenhar e desenvolver sistemas de computação. Eles atuam parte do tempo codando lado a lado com a área de produtos e parte do tempo auxiliando na operação e no incremento de sua alta disponibilidade. E de acordo com o Sr. Ben Traynor em seu livro SRE at Google, SRE é figura que aplica um conjunto de práticas, workflows, e políticas direcionadas para incrementar a confiabilidade do produto, assim como sua eficiência em todos níveis de serviço.
Portanto podemos dizer que colocando os Engenheiros em contato direto com o seu software em produção, em contato com os usuários e estabelecendo uma comunicaçao p2p (peer-to-peer), para incremento da transparência e feedback, cria-se um resultado poderoso! dando vida ao ciclo de melhoria contínua e qualidade na entrega de software e infraestrutura.
A Metodologia
Quando a prática leva a perfeição….
Através do clássico embate entre a área de desenvolvimento e a área de operações, onde os Devs querem fazer push de novidades para a produção e os Ops querem garantir a estabilidade do ambiente, o senhor Traynor sugeriu uma série e passos que formatou a base da metodologia SRE:
-> Error Budget <- Sabendo-se que 100% de uptime não é possível atingir, sem gastar pilhas de dinheiro, um SLA de 99,99% de uptime é estabelecido. Os 0,1% restantes conferem ao budget de erro, que pode ser entendido facilmente como: releases que não deram certo e possíveis falhas operacionais ou de infraestrutura, resumindo isso a minutos de downtime. Portanto uma vez que esta quota é usada, exaurida…. perdida… todos os demais releases são interormpidos, até que se restabeleça novamente o o SLA. Desta forma os Engenheiros passam a pensar duas vezes antes de realizar push de novas funções e funcionalidades em produção, melhorando assim a qualidade do seu código criado.
-> You built it — You run it <- Desenvolvedores passam a dedicar pelo menos 5% do seu tempo de trabalho para realizar atividades de Ops, como responder chamados, suporte ao usuário, on-call (Plantão), monitorar a performance do ambiente e etc… Este motto é conhecido hoje como parte da fundação da cultura DevOps, e desta forma coloca os Engenheiros para trabalhar no dia a dia da Operação, sensibilizando-os e permitindo assim que tenham novas idéias e melhore a qualidade do seu código em produção.
-> Recrutamento <- O time de SRE e Desenvolvedores compartilham o pool de profissionais, e fica a cabo do time de SREs manter este ciclo de recrutamento já que eles são especialistas, sabem como codar, conhecem o produto, sabem como melhorá-lo e conhecem o workflow do negócio e tem de maneira geral um caminho natural de evoluirem para desenvolvedores do produto.
-> Blameless Postmortem <- De maneira bem resumida… quando alguma coisa para de funcionar, não foi culpa de ninguém, possívelmente foi uma falha sistêmica, e precisa ser consertado… Este procedimento impulsiona correção, aumenta a experimentação de novas ideias, e abre espaço para inovação entre todos os times.
Devops vs SRE
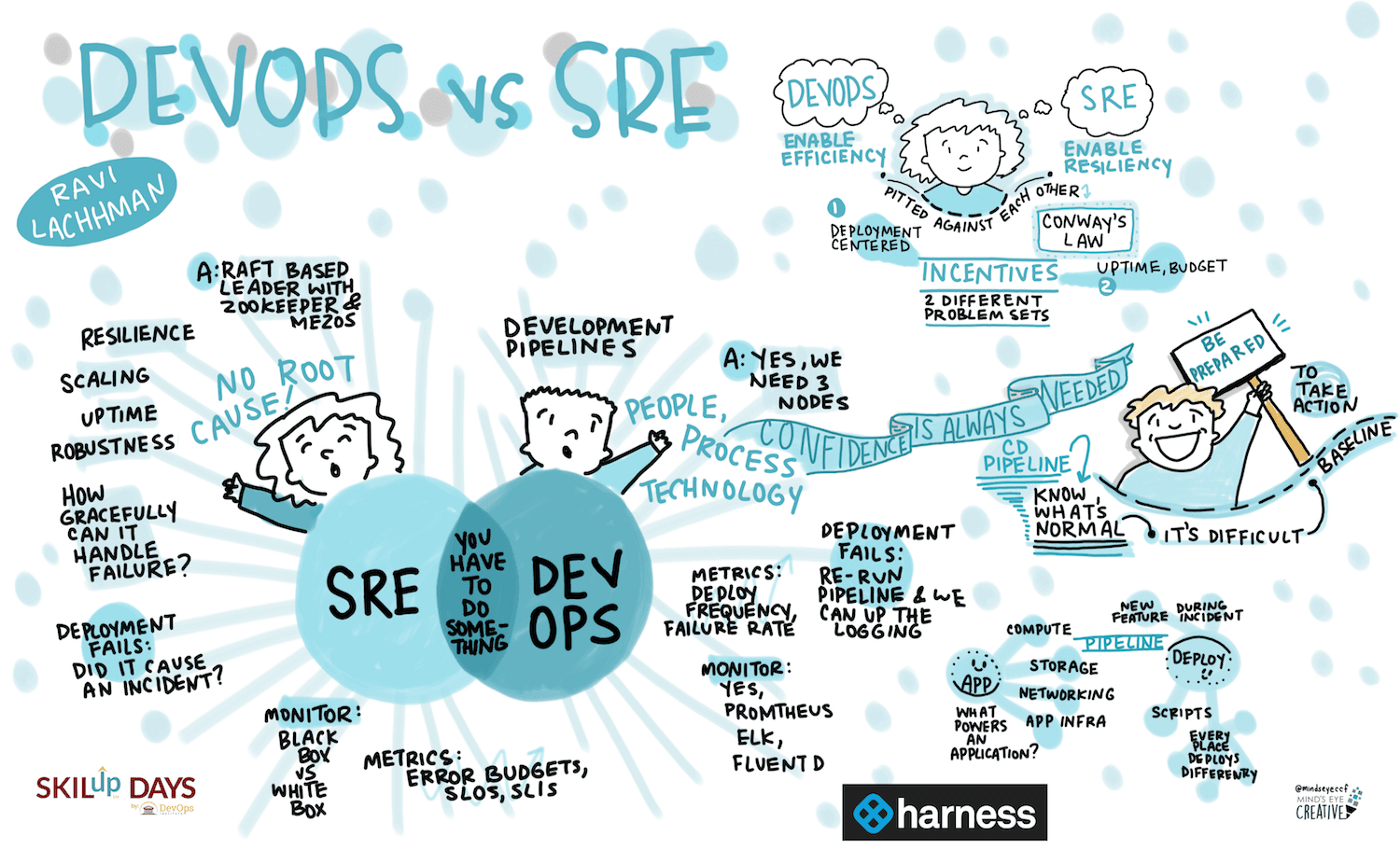
(Picture from DevOps Institute)
É possível que até aqui você já tenha pensado: Ah! Então DevOps é igual a SRE!
.
.
.
.
.

.
.
.
.
.
Como já escrevi a respeito no artigo Sobre DevOps, e de maneira resumida, podemos dizer que:
Enquanto o DevOps está centrado na automação de operações repetitivas, para maximizar a performance e diminuir a rotina, o SRE tem tudo o que foi descrito acima como objetivo, mas em seu centro de preocupação principalmente, garantir a confiabilidade de todos serviços que fazem parte do produto.
E porque o SRE é importante?
Os resultados de seu trabalho são inúmeros mas seus principais entregáveis são:
-> Diminuir o MTTR (Mean Time to Repair) e o MTBF (Mean Time Between Failures) do ambiente
-> Aumentar o tempo de entrega de Updates e correção de Bugs no ambiente
-> Mitigar o risco de falha humana através da Automação
-> Diminuir o Burnout dos colaboradore com Automação em vez de ficar combatendo somente os incêndios do dia a dia
-> Manter alinhado os esforços entre o time de Desenvolvimento e o próprio time de SREs, já que os objetivos são compartilhados
-> Aumentar os requisitos de Segurança e Compliance
-> E garantir o bom uso dos recursos através de um bom Plano de capcidade do ambiente
E como se começa esta jornada?
Antes de começar a contratar pessoas, e sair estruturando times, é bom dar uma olhada nos materiais oficiais do Google de Como os times de SREs são organizados e Sobre sua jornada
Para finalizarmos vamos resumir aqui quais são os princípios necessários para esta jornada. São eles:
-> Desenhar processos de CI/CD para automatizar o scaling de infraestrutura
-> Entender a carga de trabalho do time de Ops, e se dedicar na melhoria de suas rotinas até que se equalize, pelo menos, em 50% do tempo de trabalho em melhorias sistêmicas e 50% apagando incêndios
-> O Time de desenvolvimento deve ser sensibilizado para lidar com pelo menos 5% do trabalho de Ops. Se este percentual aumentar por conta de alguma falha de desenvolvimento, eles (Desenvolvimento) terão que lidar com o trabalho adicional
-> Criar SLAs (Service Level Agreement), SLOs (Service Level Objectives) e SLIs (Service Level Indicators) para todos sistemas e medir a performance do ambiente com base nestes indicadores
-> Criar o Error Budget com o objetivo de controlar a velocidade de mudanças no ambiente e balisar isso com a área de qualidade
-> Implementar o domínio de Observabilidade em todo ambiente, com o objetivo de monitorar de perto Latência, Saturação, Tráfego e erros de todo ambiente
-> Desenhar Cenários de falha do ambiente onde se possa criar runbooks automatizados para cada cenário, testando eles regularmente e promovendo o exercício entre os times para melhora no tempo de resposta à incidentes, mantendo assim o time sempre afiado! 😬
-> Promover sempre o rito de blameless postmortem para se mapear os erros encontrados e corrigí-los dentro do possível
-> Promover a integração entre SREs e Developers de tal forma que durante o processo de abertura de novas vagas haja a possibilidade de SREs crescerem para o time de desenvolvimento
Finalizando
Existe muito material na internet, e como o Google diz, este é um conceito em constante evolução … os Livros indicados geralmente são estes, no link, e podem ser lidos online.
Eu ainda estou lendo todos os artigos do Google relacionados, e construindo minha base de conhecimento…
😬
Espero ter ajudado!
ᕕ( ᐛ )ᕗ cya! 🎶🎶🎶
